Note: This is the second piece in our series highlighting the work, experiences, and perspectives of leaders in data visualization and analytics.
When we hop on a video call with Ben Welsh in late October, I’m immediately impressed by Ben’s background, blurting out even before we share introductions: “Is that your real office?”
He chuckles and explains the scene — a busy array of overlapping highrises and ongoing construction just across 7th Avenue from his office, where he works as Data Editor at Reuters in New York City. “You’ll know that one. That’s One Times Square, where they drop the ball on New Year’s Eve.” He points to a section under heavy development, where work on a new public observation deck and museum is underway. “People can’t go up there now, but they’ll be able to soon. It’ll be open to visitors.”

Ben Welsh in his office, with a view of construction underway at One Times Square.
It’s a fitting backdrop for the discussion that follows, which focuses largely on building things that help people better observe and understand the world around them. Ben spends his days building things, too. But instead of new observation decks and experiences for tourists, he designs and engineers back-end data pipelines that support data journalism.
“My role here as a Data Editor is to try to get more and more data out to our readers via our major outputs. So I am constantly building data pipelines, editing, and refining them down to stuff that I think might be interesting to people, and trying to get it out into the world.”
He pauses for a moment, reflecting on his response. “That was really long-winded. I use data and computers to find and tell stories. How about that?”
Building automated data pipelines to make time for more important work
Ben has been using data and computers to help tell important stories for decades. Prior to joining Reuters he spent 15 years working at the Los Angeles Times, leading and growing their award-winning Data and Graphics Department. He’s contributed to high visibility pages and stories, including the LA Times’ first live election results, an acclaimed wildfire tracker app, and “the most complete resource on the spread of COVID-19 in California.”
Less publicly visible, however, has been Ben’s work to build data pipelines and tooling that improve how those stories are created and shared. Lucky for us, he’s thrilled to bring his back-end work to the forefront in our conversation.
We’re meeting one month after Hurricane Helene devastated parts of the southeastern U.S. He uses the storm coverage as a jumping off point to describe his day-to-day work, and the benefits of automated data pipelines.
“Every time one of these events happens, it’s big news. And, every time, there are things that we repeat as part of the news coverage, like making hurricane maps so that people can see the forecast and storm path, understand the severity of the storm at different times, and know whether they need to move.”
That manual time and effort to process real-time (or nearly-real-time) data is where Ben sees opportunity.
“In the past, newsrooms may have had a specialist whose job it was to download the data files and stick them in some sort of editing tool and manually convert them into a map. But in today’s world, we can automate that. A recent task we worked on was to write a software pipeline that can discover, download, process, and refine storm data, then generate those hurricane maps within seconds of new data being released. Then, after some human review, they are sent out around the world via our different publishing streams. The same approach can work for really any newsworthy data source that has a flowing stream of information.”
One output of this effort is their new hurricane map template that compares forecasted paths from NOAA’s National Hurricane Center with other models. It’s powered, in part, by a library to access data from the Automated Tropical Cyclone Forecasting System, which Ben developed while “learning how to parse weird government data files.”
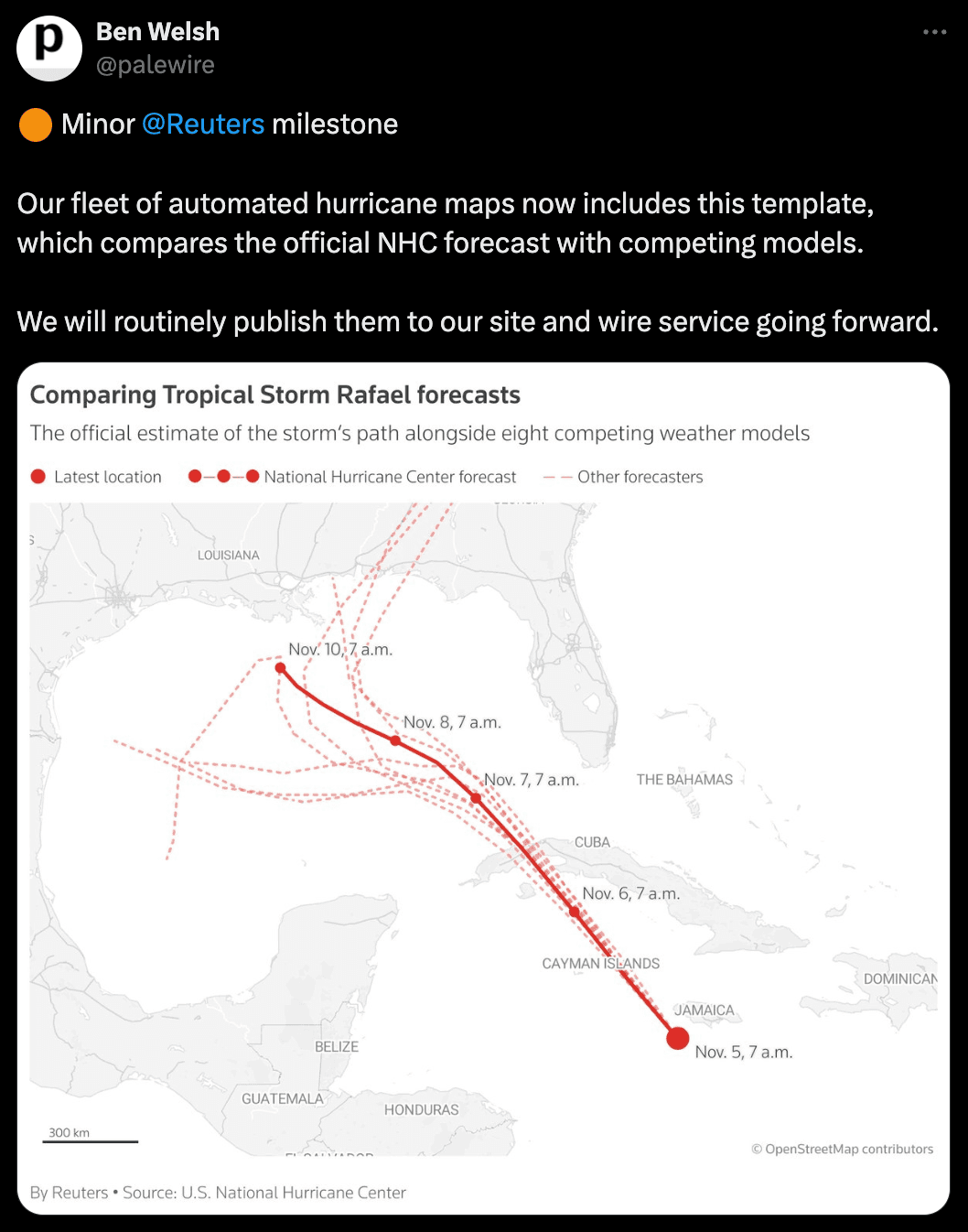
Ben recently shared a new Reuters map template that compares hurricane forecasts from the National Hurricane Center with other models.
And, instead of building a new app from scratch for each story, Ben and his colleagues are developing reusable app templates that easily integrate with their existing tools. The value of these automated pipelines and templates, Ben explains, is in helping data journalists put their energy where it matters most: “All that data work that people had to learn how to do, or had to spend a lot of time doing, was really time they weren't spending focused on what really matters, which is the story and the message.”
Innovating in a changing industry
For his back-end data engineering work, Ben’s a self-described “big Python guy,” but he nimbly jumps between thoughts on Python, HTML, node.js, and R’s ggplot2 (and the grammar of graphics more broadly), leaving no doubt that he’s a broad-spectrum polyglot.
While he has a suite of go-to tools (“back-end data engineering in Python, front-end with node.js”), he’s also quick to test new technologies, in part to stay at the cutting edge of data journalism in a tenuous time for the industry. “The entire profession of data journalism, which had been built around certain distribution networks and methods, has been totally remade by the internet. I think that that's why so many of us who stick with it — myself included — really embrace technology and innovation. It's a way that you can try to preserve these institutions that have really strong societal value, but need to evolve and adapt to survive in this new economy.”
That pressure to keep data journalism thriving in today’s news economy, along with the day-to-day struggle of working with widely different and often quirky data sources, means that Ben and his team are often early adopters of new tech.
“In the course of a given year a data journalist will look at dozens or hundreds of different data sets. We’re constantly encountering all the different weird things that can happen with data. Being the nerd caught in the middle of that mucky data processing is something that most people who work in data journalism end up liking. But it’s also why any technology that makes it easier for us is really exciting, and is why we tend to be rabid early adopters of weird new data tools.”
Being quick to adopt new tools doesn’t mean Ben is constantly on the lookout for more advanced methods, or more complex tooling. In fact, he seems most fired up about tools that offer a simpler way to do and share data work. For example, he highlights the ease of building with static site generators several times in our conversation.
"It's been great to see static site deployment really embraced. There are so many good reasons to adopt these simplified deployment routines. Static deployment can have gigantic benefits in terms of reducing financial costs, in terms of sending it out, in terms of how much time it takes to develop and publish, in terms of the risk of being hacked, the long-term maintenance costs…we can just keep going down the list."
It’s wisdom gained from experience:
“Building a dynamic website, when you really just need a static site — that’s a great way to learn the hard way.”
Ben Welsh
To demonstrate, he shares his screen to show us a static dashboard he’s recently built with Observable Framework, which acts as both a systems monitoring site for several of his automated data pipelines, and an internal resource library.
“It's basically just a simple monitoring site to keep track of our system day-to-day, updated every half hour with the latest data from the data loaders, pulled in from our logs, with all the activity loaded into a SQL database and then fed into this very humble application.”
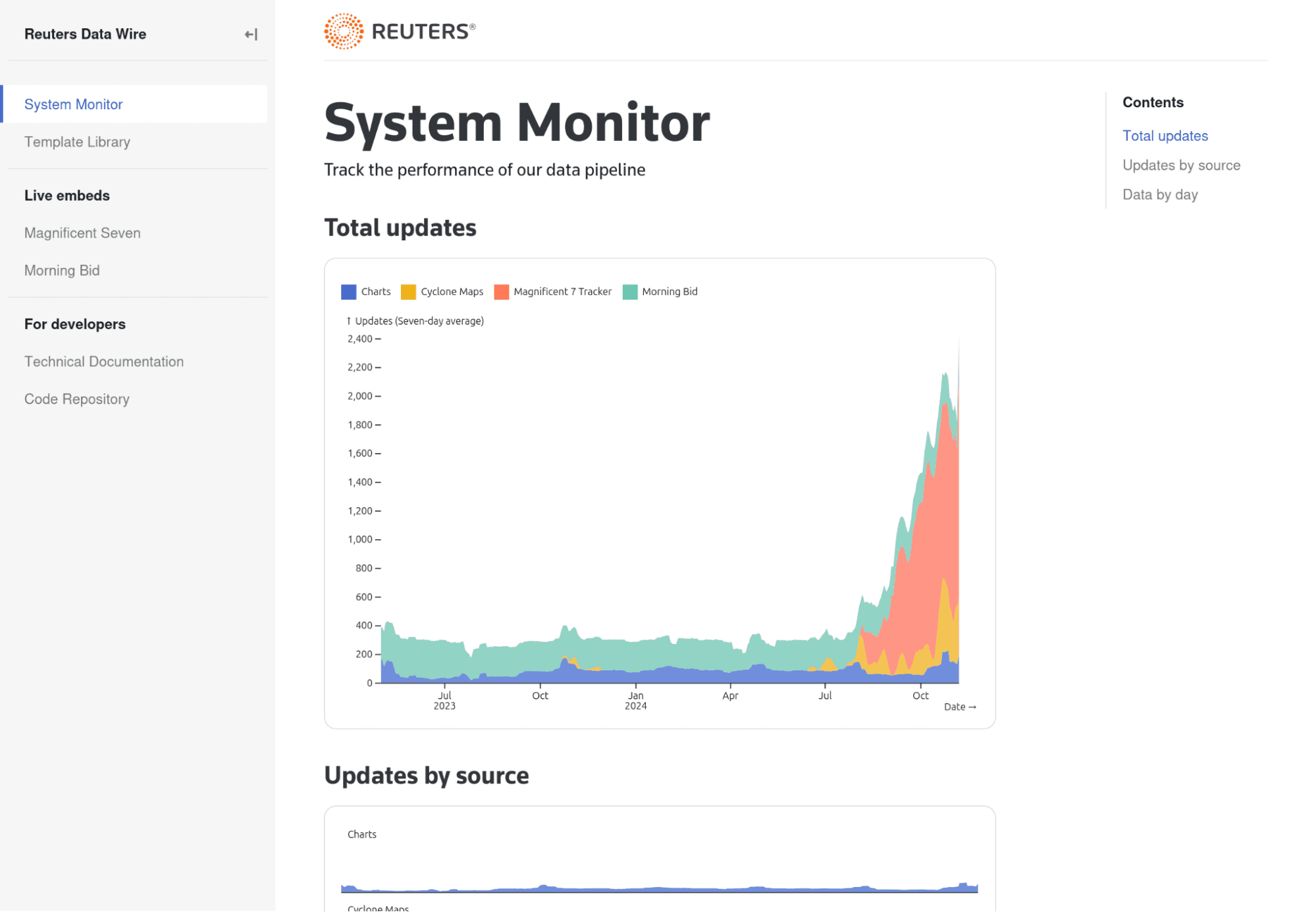
The Reuters Data Wire application, built with Observable Framework, provides updated systems monitoring data, reusable templates, documentation, and other team resources for easier tracking and reuse.
Switching to another page, Ben scrolls through several charts while commenting on the simplicity of building and getting value from the app. “The system monitor has very simple charts made in Observable Plot that let us keep tabs on what we’re pushing through day-to-day. You can pick any of the individual systems and drill down to see what’s going on with their heartbeat, or see if there's any that haven’t updated in a while (which would be a red flag). It’s a very simple monitor we had up and out in a day and a half, and it took virtually no work. And then we can add more and do more as we go, right?”
Adding and doing more with open source
Ben asks that question — “We can add more and do more as we go, right?” — offhandedly, but it captures an adventurous approach to trying and testing new tools that has permeated the conversation.
One way that’s manifested in his work is through open-source software and resources, to which he is a prolific contributor. It’s an effort he downplays at the start (“I just try to learn something new every day…”), but that has resulted in an impressive library of reusable code, software packages, templates, lessons, notebooks, websites, and more.
The breadth of tech he’s contributed to is as astonishing as the volume. APIs. Python packages. Observable Framework examples in JavaScript (like this data loader to generate a PNG from Canvas). A bot that scrapes and reports data from the U.S. Census…and one that “posts raps by Del Tha Funkee Homosapien to @MISTADOBALINA on Twitter.”
According to Ben (who at one point describes himself as a “promiscuous” learner when it comes to software), open source development can be a self-serving practice with a generous outcome.
"Open source is really part of my process of getting unstuck, learning and contributing back to the community, and also helping future me have an easier time. ‘Me’ is probably the number one beneficiary of my open-source software work. To be honest with you, a lot of it is selfish. It's really about making me more productive, happier, and less stressed. For people who wonder why we should do open source, I think that they should consider that they themselves may benefit more than they realize."
Ben Welsh
Even with so much time spent in the weeds of back-end tech and tooling, he keeps an eye on the bigger picture, frequently returning to his larger purpose: to help improve the stories that journalists can tell with data. “Open-source software allows us to collaborate with people we might think of as competitors on some of that back-end tooling stuff, so that we can compete on the stuff that really makes a difference at the end of the day.”
Looking forward and thinking...medium?
So, for someone who’s always looking for the next useful thing to learn, what exciting things are on the horizon?
To start, Ben shares a curious and cautiously optimistic view of what AI (“a truly stupendous solution in search of a problem”) can bring to data journalism, from speeding up tedious data processing tasks to making useful analyses possible for more people:
“There are recent breakthroughs in AI that are, in the true definition of the word, marvelous. From experiments I've seen, LLMs really seem to have a knack for making some traditional machine learning tasks more accessible to the average person or developer. And, we might be able to have it take on rote or basic tasks when it comes to data pipelining and cleaning. Being able to better democratize a lot of our data work has a lot of power.”
However AI ends up impacting data work for journalism, Ben hopes that even the conversations it has spawned will inspire forward progress.
"I've just really loved how the excitement and hype around AI has started a lot of conversations about automation in general, whether it ultimately involves an LLM or not. The interest, the capital, the conversations that have been started in this recent bubble that we're all inflating together — I think these can be harnessed for good and our shared profit if we focus on how we can use automation and structured thinking about information processing."
Ben Welsh
While discussions around AI often focus on rapidly advancing LLMs trained on massive datasets, Ben is also thinking a bit smaller, sharing shortcomings he sees with how data journalists can visualize and tell stories with “medium data”.
“On one end is big data — the gigantic copies of the Internet that fill up Google data centers…so big, you can't even comprehend it. On the other is small data, where you can see everything in a single spreadsheet. But more and more, data journalism projects fall into this middle space that I call ‘medium data.’ There haven't been very good tools for dealing with 10 million, 50 million records for either back-end analyses or, especially, front-end data visualization and publishing. How do I put a hundred thousand points on a map without crashing my user’s browser? What about when they're on a mobile phone with weaker Internet or processing power?”
He gives another nod to static deployment as a step in the right direction for medium data, adding, “It’s been really great to see this innovation happening now in the static world and with other new tools that mean we can have all the benefits of static site publishing, while being as ambitious as we can dream of being in terms of how much data we bring to bear. I think that that's something that's still percolating, and it's a really exciting place to be.”
As we wrap up the conversation, Ben casually remarks on how our call fits into his day:
“Was I too nerdy? In my day-to-day job, I don't get to be too nerdy. This is the only conversation I'll have all day about code. The rest of it’s going to be about news.”
Coming from someone who works daily to cut down on time spent coding to make more time for creating and sharing important stories, we think that sounds about right.
A huge thank you to Ben for sharing his work, experience, and expertise with us. Learn more about Ben, and check out his open-source contributions.
See how Observable can help your team build and host custom, interactive data apps and dashboards at observablehq.com.