When working in Observable Framework, you can build faster, richer data apps by precomputing data snapshots at build time with data loaders. Data loaders can be written in any language (Python, Rust, Julia, SQL, R, etc.) as long as they send their payload (usually a data snapshot formatted as a CSV, JSON, image, parquet, ZIP archive, etc.) to standard output.
The process of writing data loaders might feel a bit unfamiliar at first. For example, how can you see what’s generated by a data loader as you work? Where should you look for clues when something goes wrong? And how can you set yourself up for success? In this post Observable team members share useful tips to help you write and troubleshoot data loaders. Let’s dive in!
Tips for writing data loaders
Embrace the flexibility: choose your tools
Data loaders can be written in any language and with whatever libraries you choose. We encourage you to embrace data loader flexibility, and write loaders in the language you feel most confident using for the current task.
Fil Rivière (Data Visualization Engineer) shares:
[A data loader is] just a program. Any program. You can use anything that runs on your computer.

Fil Rivière
And, as Michael Cooper (Senior Software Engineer) highlights, that means you can choose to write them with familiar tools:
One of the things that’s important is you shouldn’t be intimidated. [Data loaders] are normal programs. It should be something very familiar — data loaders are designed to meet you where you are.

Michael Cooper
So get started on the right foot when you set out to create a data loader. Choose the language and libraries you’re comfortable with to set yourself up for success.
Run the data loader
This one might seem obvious, but we sometimes overlook obvious strategies when getting started with a new workflow. So remember: you can manually run data loaders to get a quick view of the output. Since the generated file is sent to standard output, you’ll see the printed output in the terminal for most formats.
Mike Bostock (Founder, Office of the CEO) recently responded to a question about troubleshooting data loaders:
Data loaders are just programs, so you can run them manually. For example you can run a JavaScript data loader as node src/foo.csv.js.

Mike Bostock
Cobus Theunissen (Head of Customer Success) notes:
One of the things that I found tricky was running a TypeScript data loader, since it needs to be compiled to JavaScript in order for node to run it. I just use npx tsx src/data/loader.xxx.ts, which compiles the TypeScript on the fly.

Cobus Theunissen
Let’s look at an example. The sample Julia data loader below (src/data/chinstrap.json.jl) generates a JSON file:
using CSV
using DataFrames
using JSON3
chinstraps = CSV.read("src/data/penguins.csv", DataFrame) |>
filter(:species => ==("Chinstrap"))
chinstrapsJSON = JSON3.write(chinstraps)
println(chinstrapsJSON)When the loader is run — either from the Julia REPL using include("src/data/chinstrap.json.jl"), or from the command line with julia src/data/chinstrap.json.jl) — we see the following printed (only the first line is shown for brevity):
{"columns":[["Chinstrap","Chinstrap","Chinstrap","Chinstrap","Chinstrap",...
Don’t expect this to be the cleanest view of your data snapshot. Michael notes that “When you run the data loader as a script, sometimes it might dump out a lot of information if it’s working.” Despite the display, it does quickly confirm some important things: the loader is sending something to standard output, and it looks like data in JSON format. Both are good clues that we’re on the right track.
There are some output types (e.g. ZIP archives and images) that won’t display in the terminal. In those cases, you can send data loader standard output to a file, e.g. with node src/foo.json.js > foo.json, then view the file with any program that can open it.
Display generously in live preview
Changes to data loaders are reflected in live preview. That means you can display code and content as you iterate to check data loader outputs.
The sample data loader below (magic.json.js) generates a JSON file with information about Magic: The Gathering cards from scryfall.com:
import * as d3 from "d3";
const url = "https://api.scryfall.com/cards/search?order=cmc&q=c:red%20pow=3";
const magicCards = await d3.json(url);
const magicCardsData = magicCards.data.map((d) => ({
name: d.name,
release: d.released_at,
mana_cost: d.mana_cost,
set: d.set_name,
rarity: d.rarity
}));
process.stdout.write(JSON.stringify(magicCardsData));FileAttachment() below accesses the output, magic.json, in a Markdown file, and display exposes the value. The echo option additionally exposes the code, which can be helpful during development:
```js echo
const magicCards = await FileAttachment("data/magic.json").json();
display(magicCards);
```

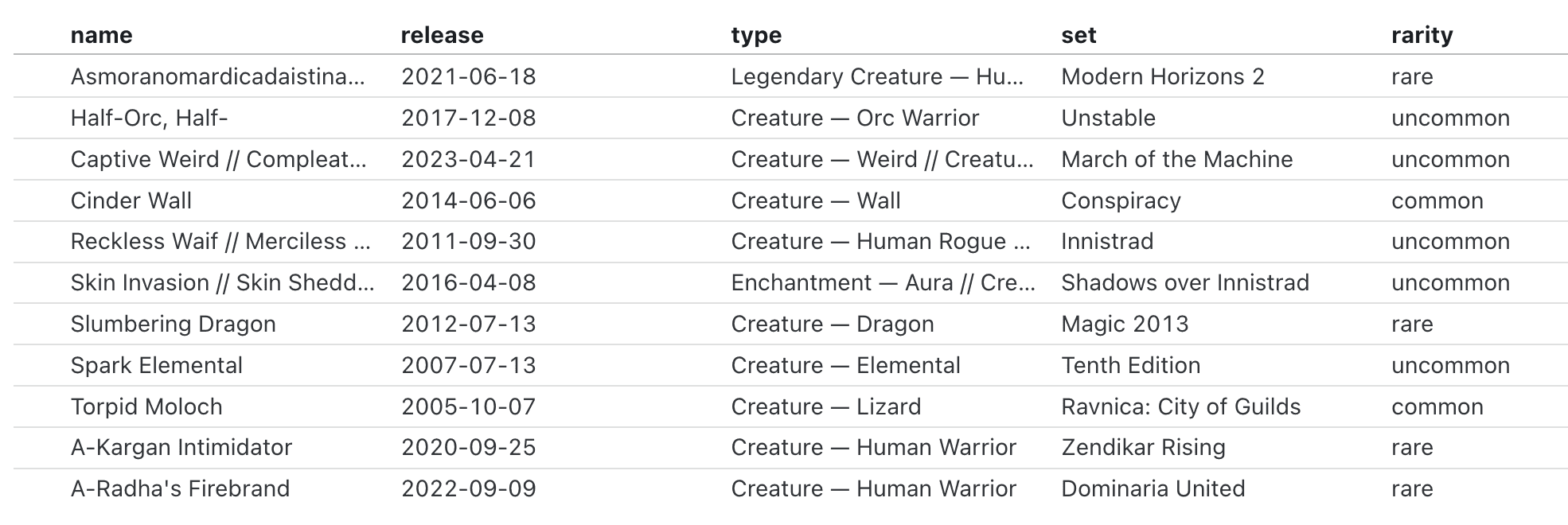
We can view the output in a nice table with Inputs.table():
```js echo
display(Inputs.table(magicCards));
```
First aim for “it works,” then optimize
Drafting data loaders can feel like a bit of a “chicken or the egg” scenario. Egg: you need to write a loader to get a data snapshot from which you can start developing visualizations. Chicken: data loaders should be tailored to only generate data that gets used in visualizations. But how do you know the minimum data snapshots you need until you’ve prototyped the visualizations?
Paul Buffa (Director of Business Intelligence) advises:
Start simple and don’t focus too much on optimizing the data loader at first. The visualization drives the data loader, so first you need to know what the visualization needs. Then, you can update the loader to optimize build time — but that doesn’t need to be your first step.

Paul Buffa
Early versions of a data loader will almost always send more than you need to the client. That’s okay. Get your draft data loader up and running, get a better sense of what your visualizations require, then focus on optimizing a data loader to minimize what gets loaded by the page.
For data loaders and client-side queries, we ❤️ DuckDB
Several Observable team members mentioned how writing SQL queries using DuckDB improves their data loader performance and development experience. In Framework, you can use DuckDB for fast data loaders and SQL queries in Markdown files.
Related to his tip about “get it working first, then optimize” above, Paul shares this strategy for quick iteration, recommending client-side SQL queries in Markdown for faster development:
You don’t have to pull straight from the warehouse every time. Just pull in more with the data loader in a rawer format, then use SQL code blocks with DuckDB in Markdown to query and iterate more quickly.
Paul Buffa
Then, you can easily adapt queries you’ve honed in a Markdown file to optimize a DuckDB-powered data loader.
Fil likes DuckDB for flexible, efficient data loaders and client-side queries:
DuckDB is a rising star, which you should use for data loaders. It digests any data source, and is very efficient at every level.
Fil Rivière
So give DuckDB a shot! Learn more about SQL in Markdown, and see an example data loader powered by DuckDB that emits a parquet file.
Tips for troubleshooting data loaders
See logged error messages
When writing data loaders, there are different ways to see logged messages and errors.
First, check for errors returned by the preview server. The preview server watches data loaders and automatically re-runs them when changes are made. Errors thrown during execution are shown in the preview server log.
Below, an error returned for a Python data loader (where the variable name should be Birth_Rate, but is incorrectly written as Birth_rate) is shown in Framework’s preview server log:

If you’ve tried to access the output of a data loader on a page, you will also see an error returned there, typically like:
RuntimeError: Unable to load file: birth-statistics.png
You can create your own log to see what’s returned at useful checkpoints in your data loader. Remember to log messages to standard error, not standard output, so that generated messages aren’t included in the output file. In JavaScript data loaders, for example, use console.warn to log to standard error (rather than console.log, which writes to standard output).
Check that everything is installed
When you write data loaders, any modules, packages, and libraries used in the loader must be installed.
If you’re getting an error about modules or libraries not existing in the preview server log (like code: ‘MODULE NOT FOUND’), make sure you’ve installed everything you’re using in a data loader — in the right place (e.g. if using a virtual environment).
Another thing to keep in mind: Framework’s recommended libraries are available out-of-the-box in Markdown files, but they are not implicitly imported in data loaders. For example, you can use D3 functions in JavaScript cells in Markdown without importing D3, but you’ll need to explicitly import it for use in a JavaScript data loader, e.g. with:
import * as d3 from "d3";
Explore the cache
Files generated by data loaders are stored in the cache at src/.observablehq/cache. That means you can view the files in the cache to explore the outputs.
If you’re struggling to load the output of a data loader in a page, Fil recommends:
Try opening the file from the cache. If you expect a JSON and it doesn’t open, just open the file in a text editor and see what it spits out.
Fil Rivière
That can be useful for debugging. For example, if you’re expecting to see data in JSON format but you instead see a series of warning messages, you might check to see if you’ve logged messages to standard output instead of standard error.
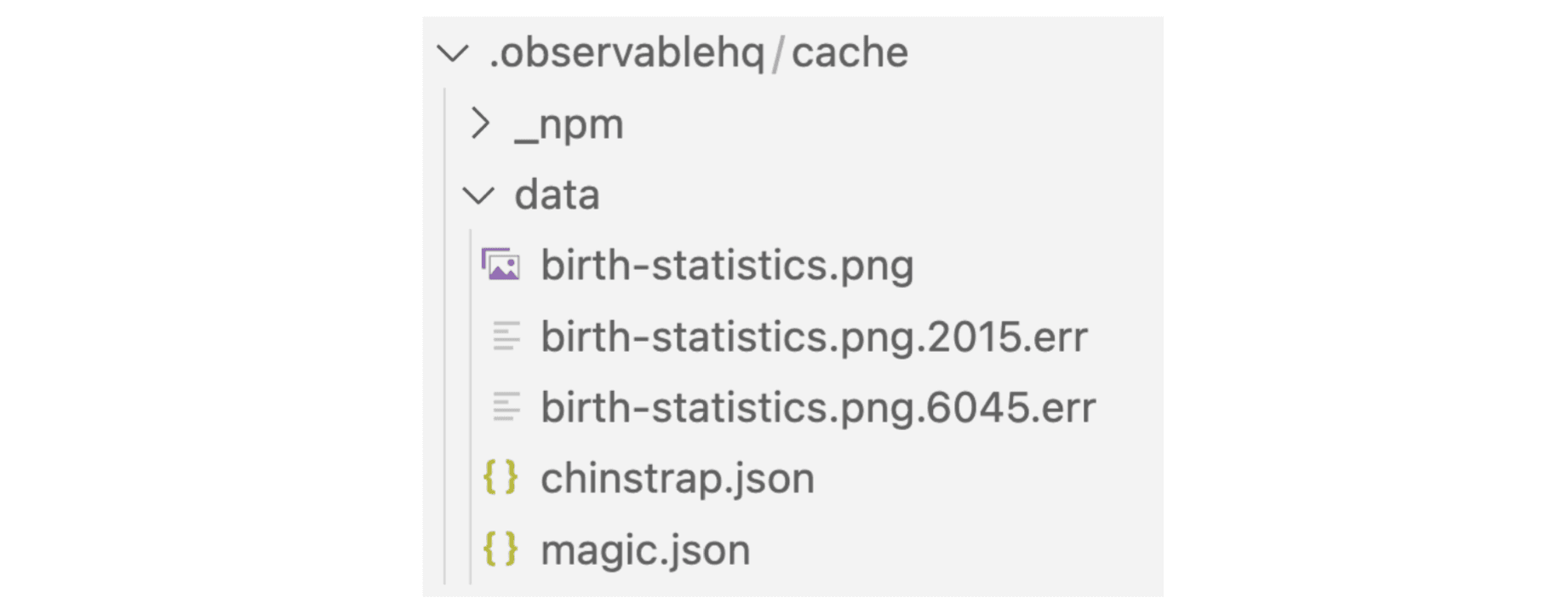
Cached file names provide an additional clue. If there is an error during data loader execution, the generated file ends with a numeric identifier and .err suffix.
The cache below contains three files generated by functional data loaders (birth-statistics.png, chinstrap.json, and magic.json), and two (birth-statistics.png.2015.err, birth-statistics.png.6045.err) from data loaders that exited due to error:
You can force a data loader to re-run during development or on build by deleting the generated output. For example, on Unix machines you can remove entire observablehq/cache directory with rm -rf src/.observablehq/cache. Or, include the file name to remove the output for a single data loader (e.g. rm -f src/.observablehq/cache/chinstrap.json).
Start writing data loaders
We hope these strategies encourage you to take the plunge into writing and troubleshooting data loaders. If you’re new to Observable Framework, we recommend following our Getting started tutorial, which includes a friendly step-by-step introduction to creating and editing your first JavaScript data loader. Then check out our Framework documentation to keep building fast, rich data apps with code.